# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface from itemadapter import ItemAdapter import json
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。开发爬虫过程中,经常会发现反爬措施非常重用,其中设置随机user-agent就是一项重要的反爬措施,Scrapy中设置UA的方式有很多,在教程最后的进阶操作中,笔者会介绍两种常见方式。
这里设置一个UA为例,如下:
1 2 3 4 5 6 7
# settings.py文件中找到如下代码解封,并加入UA: # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36', }
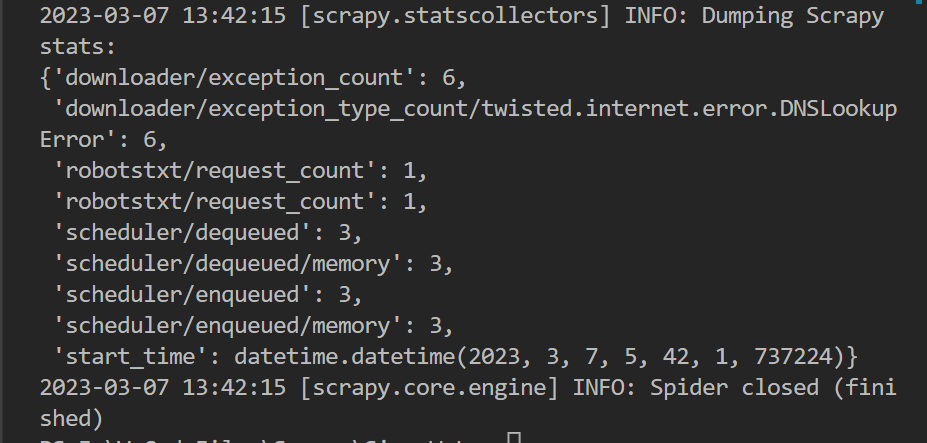
9.到目前为止,一个入门级别的scrapy爬虫已经OK了
如何运行?
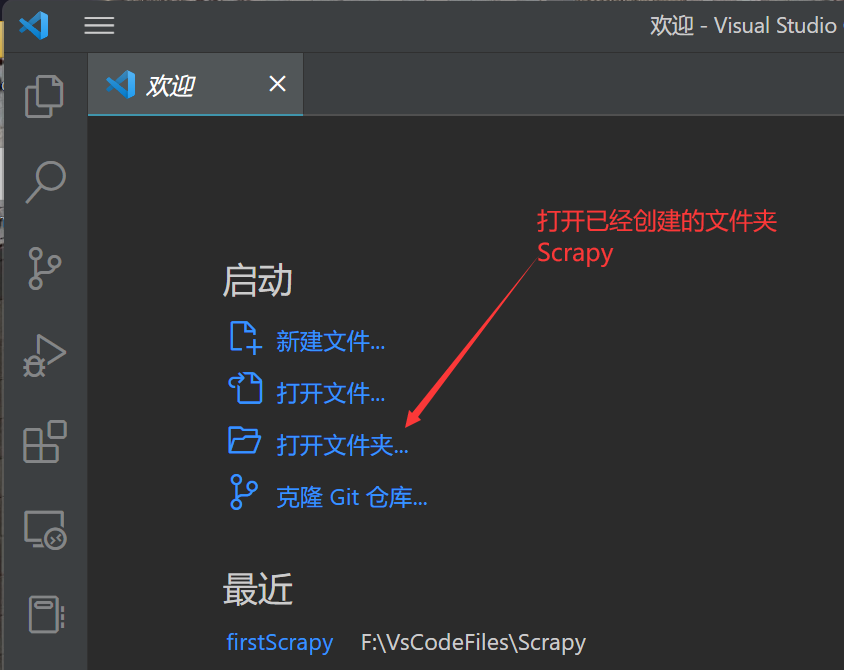
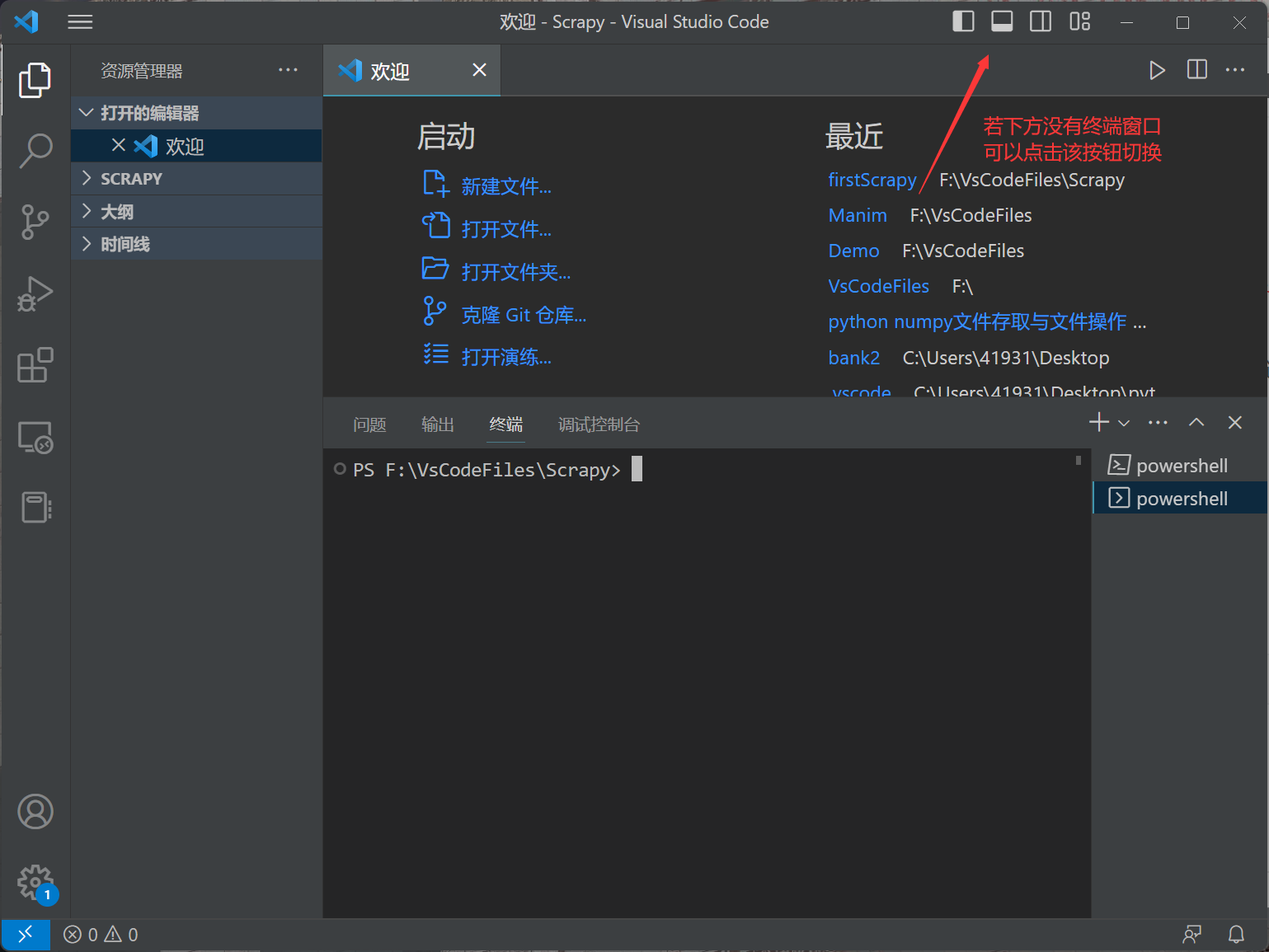
现在cd到项目目录下,在终端中输入
1
scrapy crawl SivanInfo
即可运行scrapy!
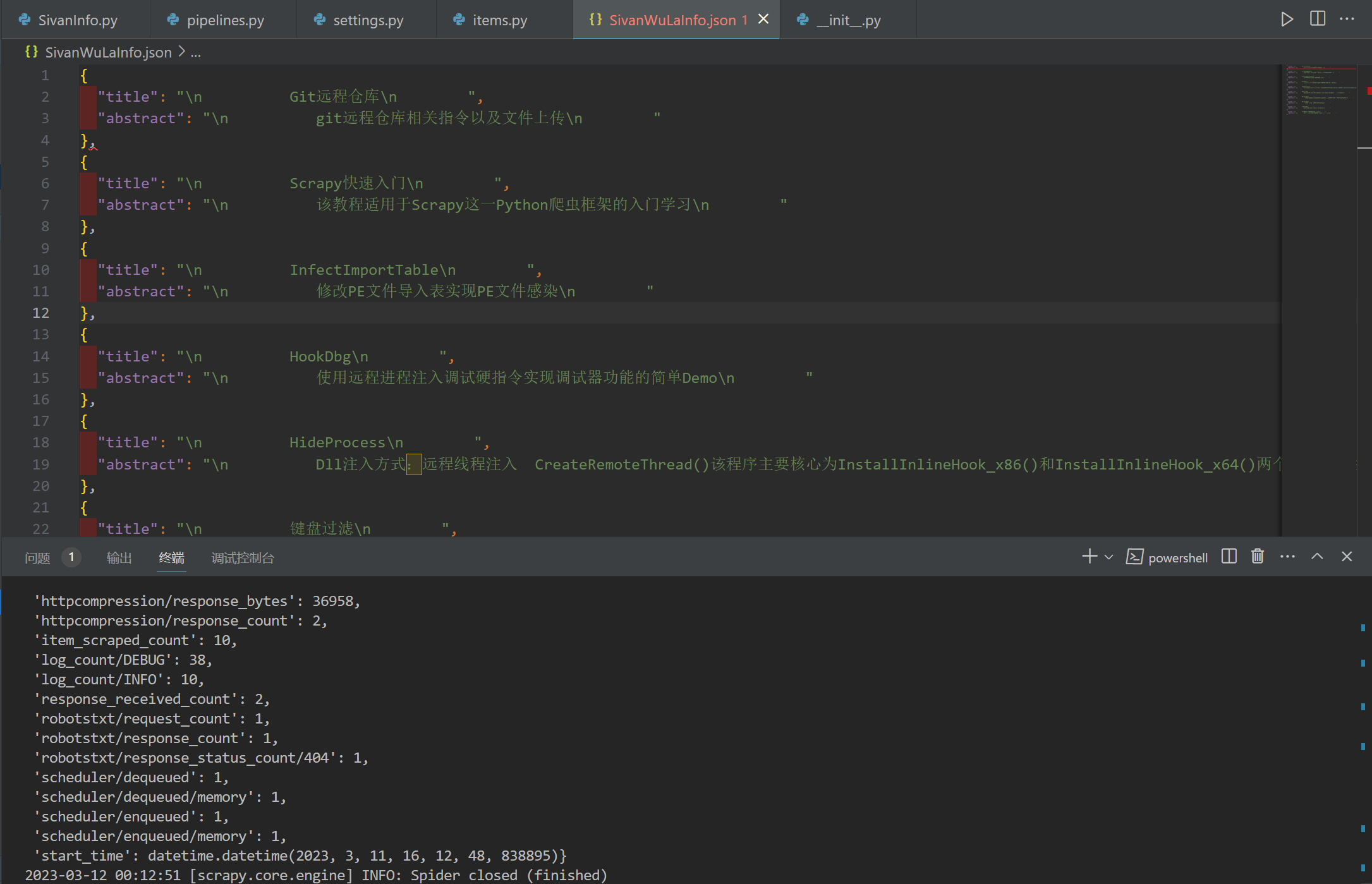
如上图,笔者网页文章板中,读者所感兴趣的信息已经被写入json文件中
第三部分 进阶操作
1.随机设置User Agent
这里提供两种方式:
(1)settings创建user agent表
导入random,随机用choise函数调用user agent
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import random # user agent 列表 USER_AGENT_LIST = [ 'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23', 'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)', 'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)', 'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)', 'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)', 'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0', 'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)', 'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)' ] # 随机生成user agent USER_AGENT = random.choice(USER_AGENT_LIST)
import random classUserAgentMiddleware(object): def__init__(self): self.user_agent_list = [ 'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23', 'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)', 'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)', 'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)', 'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)', 'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0', 'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)', 'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)' ] defprocess_request(self,request,spider): request.headers['USER_AGENT']=random.choice(self.user_agent_list)
defparse(self, response): # We want to inspect one specific response. if".org"in response.url: from scrapy.shell import inspect_response inspect_response(response, self)